❮ 2023-04-23
On being an external developer
- Project details:
- Technical debt vs. being an external developer
- Problems
- Our efforts to make the experience less catastrophic for externals
- tl;dr
Project details:
- Project from a huge German corporation, staffed mostly in-house, we support them and are seen as normal team members.
- The Tech-Stack kinda aged over the time, still at Java 1.8 and Scala 2, Frontend in JavaFX.
- Everything is hard-wired and so hard to decouple, but attempts to change that are being made right now.
- Frontend -> Backend communication done via Kryo -> Switch that to JSON API
- DAO Layer uses Scalikejdbc with a lot of db2 specific queries, hard to replace it with something else.
- A large mainframe is used to fetch and persist data (DB2 on z/OS), that is entirely administrated by another department
- As an external, you are basically on your own to make your everyday-coding-experience not terrible.
Technical debt vs. being an external developer
The state in which the project got maneuvered into isn't even a big deal if you are an in-house developer and, of course, was not the intention from anyone wanting it to be like this in the first place, I surely don't want to blame anyone. It's just the regular mixture of being pressured developing new features and having no room to reevaluate technical decisions, doing this over nearly 8 years took its toll.
But from the inside you don't notice much pain, you have every tool you need available inside the intranet, every service works out of the box like it did for years now, no major infrastructure change is on the horizon, and the backlog is full of user-stories anyway, so why allocating time to change something that just works™️?
So as their working day was not really affected at all, as soon as we entered we got confronted with all sorts of issues that made working on the project quite challenging:
- We don't get intranet access via VPN, because it is not possible due to company policy, so we cannot connect to their databases.
- We got provided access to a Citrix-VM that was able to connect to all services we'd need, but:
- Compile times are around 20 to 25 Minutes
- At normal working hours, the VMs are so slow that they're basically unusable
- They are seriously under powered so doing actual work on them was nearly impossible (Dual- to Quad-Core, 8 Gigs of RAM)
- The Session gets closed after some minutes of inactivity, relogging would result in a fresh session, so all previous context is lost, and you'd have to recompile everything again.
- Replacing the DAO-Layer with something else like MySQL/PostgreSQL is impossible due to the sheer size of the codebase.
- Buying our own Mainframe would be "a little" over the top
So what should we do? Luckily, there is DB2-LUW, a software that enables us to run a local DB2-Instance on our machines. Setting this up took me a lot of time and I don't know if I ever would call this task finished, because we still keep running in issues (2 years later).
I had to:
- Get a copy of the official DDL Script that was nowhere around anymore and had to solve some LUW-z/OS incompatibilities, that I only "found" by running into runtime errors while developing.
- Get Test-Data: Due to strict confidentiality requirements we could only get a subset of 5-year-old data, so if we need to work with real-world data, e.g. to reproduce production bugs, we'd still have to use the Citrix-Client.
- Set up a container infrastructure, so every external developer is able to deploy it without that much effort.
- The Docker Image of it is x86 only, so pretty slow on M1-Macs due to the emulation that does not support Rosetta-2 translation.
- Overwrite the Applications-Config to be able to connect to another database.
Problems
Here is just a list of memorable problems we had:
No support for M1 Macs
Even after 2 years after release no support for m1 macs, guess it'll never be there, but maybe emulation gets better in a few months.
There is a support thread inside the IBM Community-Forum about this topic.
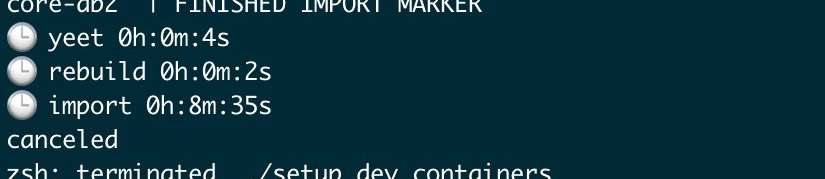 Import time on x86
Import time on x86
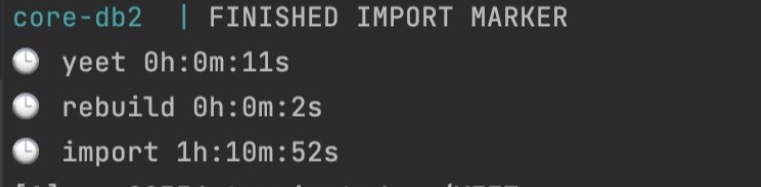 Import time on m1 macs
Import time on m1 macs
Current State (April 2023): It works with x86 Emulation, but it is terribly slow compared to native speed, so I have to run an additional mini pc at home that sips quite a lot of energy, quite unfavorable with today's energy prices, using another instance via VPN was impossible because the apps' performance suffered a lot with latency. There is a beta functionality right now to let Docker use Apples Rosetta-2 translation layer for x86-images, but that is currently not working for DB2-LUW:
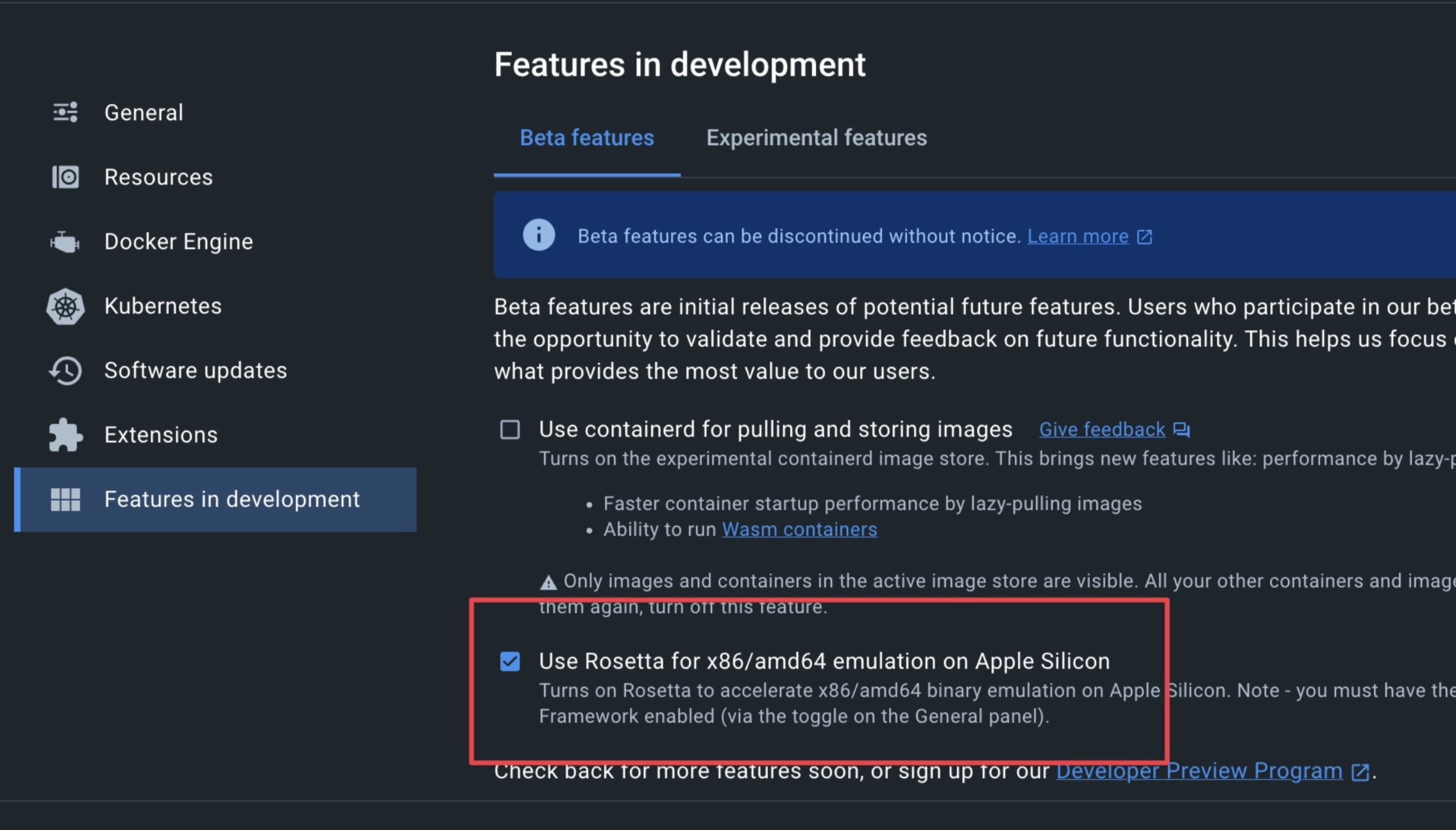 Rosetta 2 Emulation Beta in Docker
Rosetta 2 Emulation Beta in Docker
 ..that is not working atm sadly
..that is not working atm sadly
Incompatible queries between LUW and z/OS
Some SQL Queries are not 100% compatible, for example the "Inner Join" keyword is not allowed in recursive queries.
And the "Merge Into" Command fails on LUW if there is a "NOT ATOMIC CONTINUE ON SQLEXCEPTION" in it.
These 2 two errors were pretty easy to fix, but hard to spot because everything just crashes only on runtime, and we are still not sure if we found every compatibility issue just yet, what is pretty terrible from a workflow point of view: You actually want to work on a user story but worst case you have to troubleshoot yet another kind of obscure database-compatibility-error, and it happened a LOT.
Randomly corrupted archives after importing data
That error foreshadowed a little within the previous screenshots and was by far the hardest one to catch. At one point in time, a colleague contacted me because of this error:
 DB2 Error -1448
DB2 Error -1448
That error appeared every time he used a specific feature of our app, I could not reproduce it with my local build, so I threw away his local docker infrastructure and rebuilt everything, but the error remained. So I did the same with my infrastructure and compared the log files:
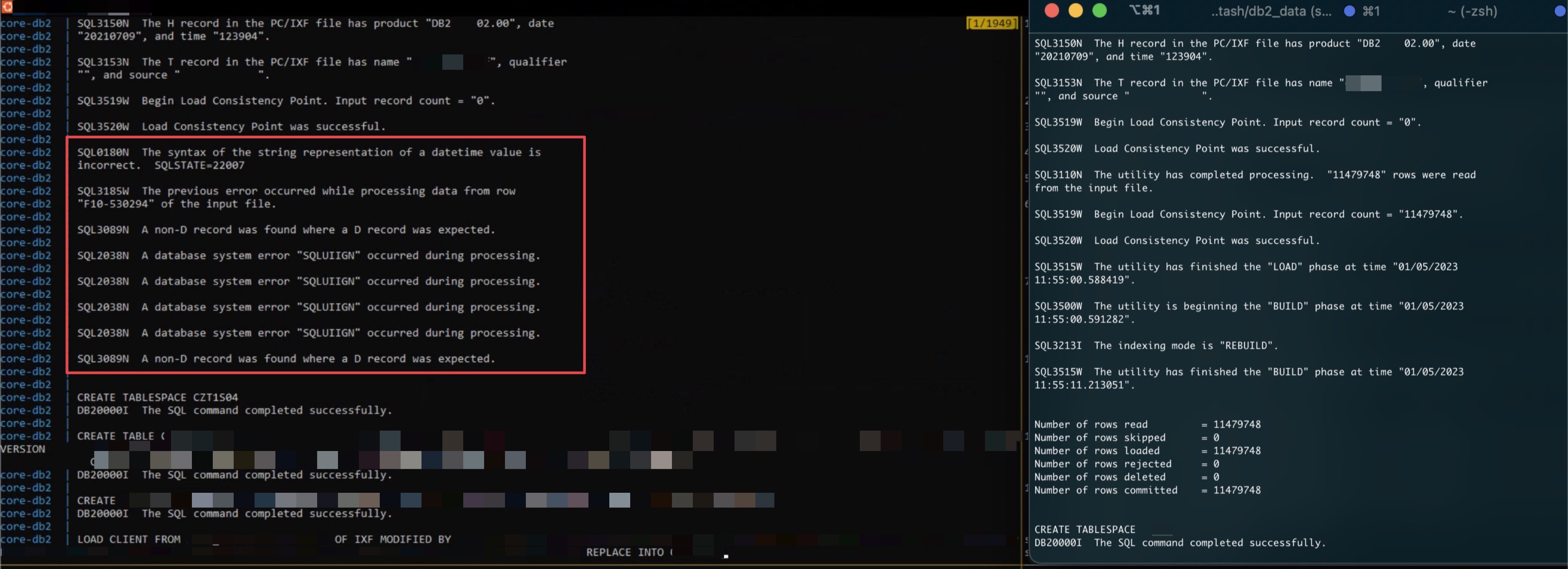 Left: His log, Right: My log
Left: His log, Right: My log
Seems like that while importing our test-data, his importer chokes on some archives, looking at them with a hex-editor revealed that some files got corrupted.
 Corrupted Data
Corrupted Data
We re-downloaded these exact archives and noticed that it happened again once the import finished. At first, I thought his HDD was broken, but I also looked at our docker-compose file again and noticed that the docker container had write access to these archives right now. I quickly changed the mount to be read-only, re-downloaded the archives once again and started over, no corrupted archives anymore.
Conclusion: Sometimes the importer destroys parts of archives as long as the process has write access to our files that we want to import, a "feature" that I certainly did not expect from an import tool. After that I wrote a few file validation and downloading scripts to be able to check pretty quickly if files were corrupted on our machines, turns out at least one archive was always corrupted on every developer machine and server-vm:
 Corrupted Data
Corrupted Data
Til now I don't know what caused this behavior, if it is a bug, some kind of weird side effect or something else, I only know how to mitigate it by mounting everything read-only that is not supposed to get changed.
Our efforts to make the experience less catastrophic for externals
Switch over to JOOQ
JOOQ auto-generates boilerplate java code out a DDL and gives us a lot of compile-time-safety while writing queries. When the DDL changes, the boilerplate-code does also, and you get compile-time-errors everywhere you need to change your code. Without that, you are basically blind and have to rely on your unit- or integration-tests to make a good job of finding errors.
ScalikeJDBC doesn't have this functionality at all, what currently is one of our biggest problems. Doing large changes to the underlying database-structure is always coupled to do a lot of manual testing and refactoring, what costs us a lot of time and gives us nearly no freedom to refactor existing logic, code and data-structures.
Also, JOOQ provides some kind of "cross-database" support for databases, so we could use a MySQL or PostgreSQL database for our local machines and get rid of the horrible local db2 experience, but being database-agnostic prevents us from using currently needed database-specific feature-sets like temporal-tables from db2, or the merge-into statement. MySQL for example does not support any of it, PostgreSQL has extensions for it, but it would still be hard to set it up.
Furthermore, using JOOQ with DB2 as Database costs money because you need a corporate license, another hurdle you cross, e.g. you have to find some good arguments for your PO to justify the extra costs.
Also, the old tech-stack took its toll, there were no JOOQ-Autogen plugins available anymore for SBT that are compatible with Java 1.8. We could use older versions of it, but that would create other problems as well.
In the end we gave up the dream to have JOOQ inside the project because it would take too much time to move everything over, and the companies infrastructure does not allow it to move from DB2 to something else without that much friction anytime soon.
Trying a different Database
Same with JOOQ, too many incompatibilities and too little time to set up a database agnostic solution.
Introduce Database-Versioning with Flyway
We successfully did this with another MySQL-Database that got used inside the project, but for DB2 it won't happen. Firstly, we don't have write access to all schemas, and we decided to not allocate any resources to implement it there because the data-model is not supposed to change drastically anymore, so we are staying with the status-quo, but it would be so nice to have this for writing unit-tests for our DAOs.
tl;dr
- We externally support in-house project inside large corporation
- Project is hard-wired to infrastructure we don't have access to and that is very hard to mock, provided working environment is unusable
- Huge amount of effort taken to mock everything needed, still in the process of modernizing tech stack and decoupling front- and backend
- Bureaucracy and tight deadlines make everything harder
- Learned a lot on what to look at in a project lifecycle